What We’ve Built & What Actually Changed
Every case study reflects how we approach challenges with intent while balancing business insight, user needs, and technical precision to create meaningful change.
- All Industries
- Cybersecurity
- EdTech
- Energy & Utilities
- Gaming & Entertainment
- Legal Services
- Life Sciences & Healthcare
- Manufacturing & Industrial
- Market Research
- Retail & eCommerce
- Telecom & Media
- All Technologies
- Android
- Angular JS
- Digital Marketing
- Flutter
- HubSpot
- iOS
- Javascript
- Magento
- Moodle
- Next.js
- Node JS
- React JS
- Salesforce
- Vue.js
- Wordpress
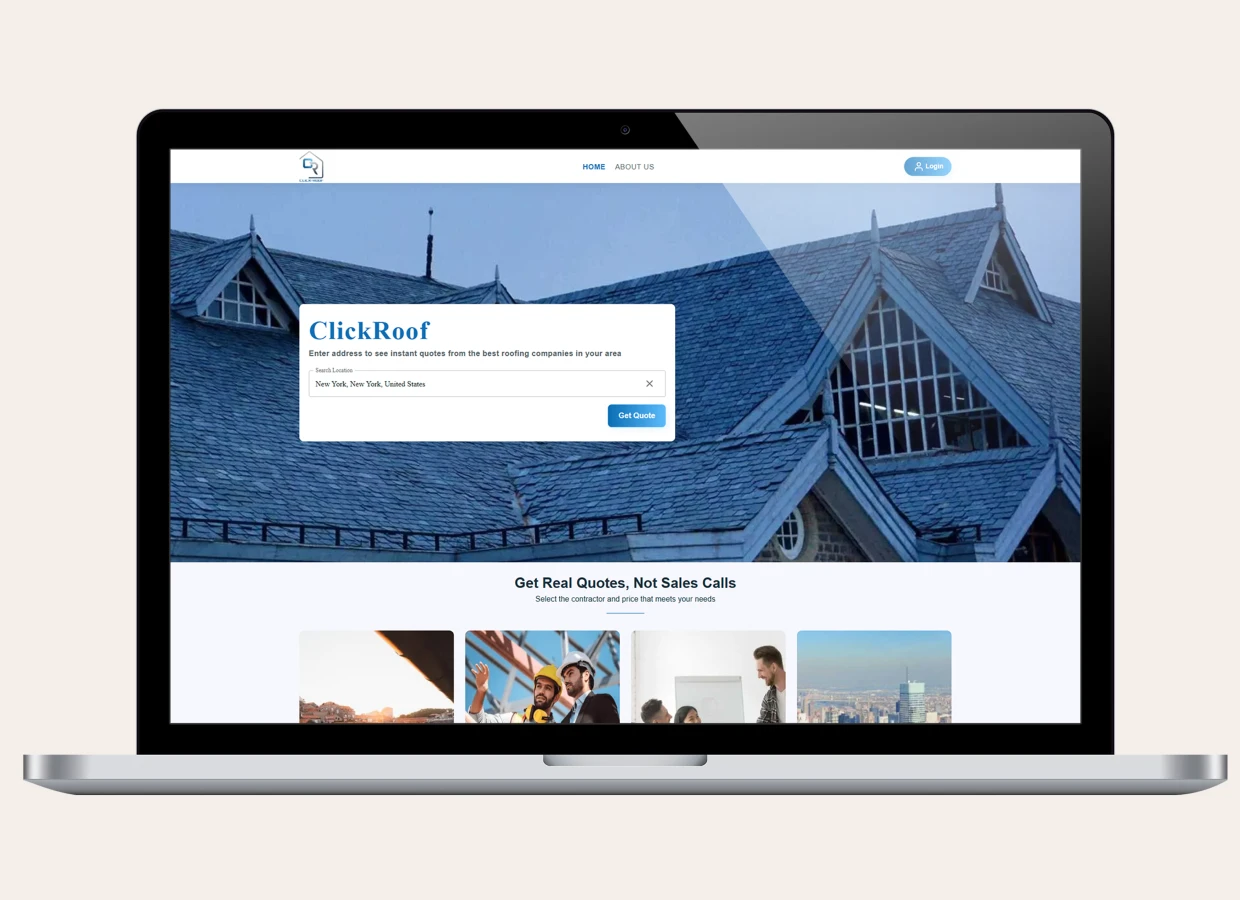
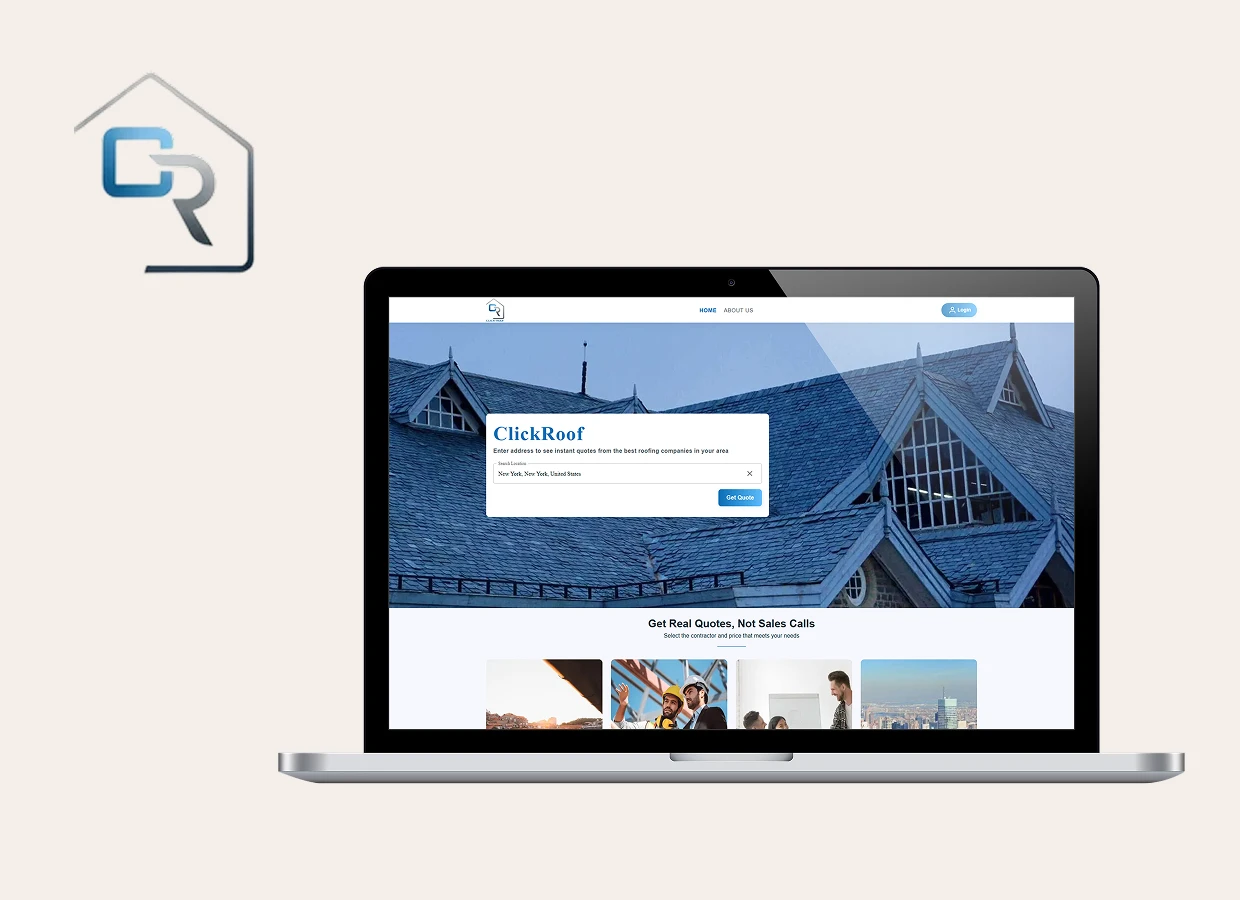
Changing Roofing Estimates with Location Intelligence and Real-Time Pricing
Tech Stack
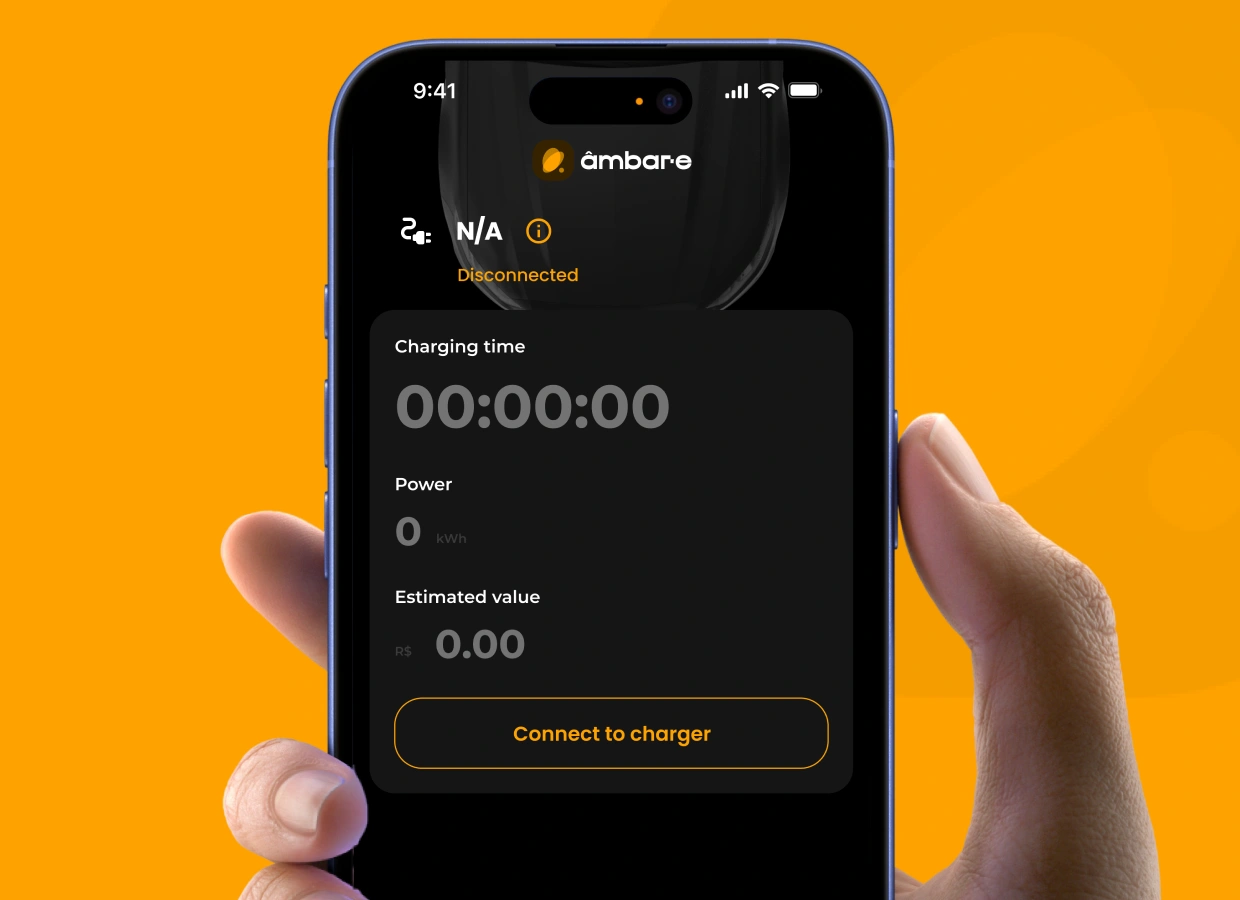

How We Built Brazil's Driver App for Electric Vehicle Charging?
Tech Stack
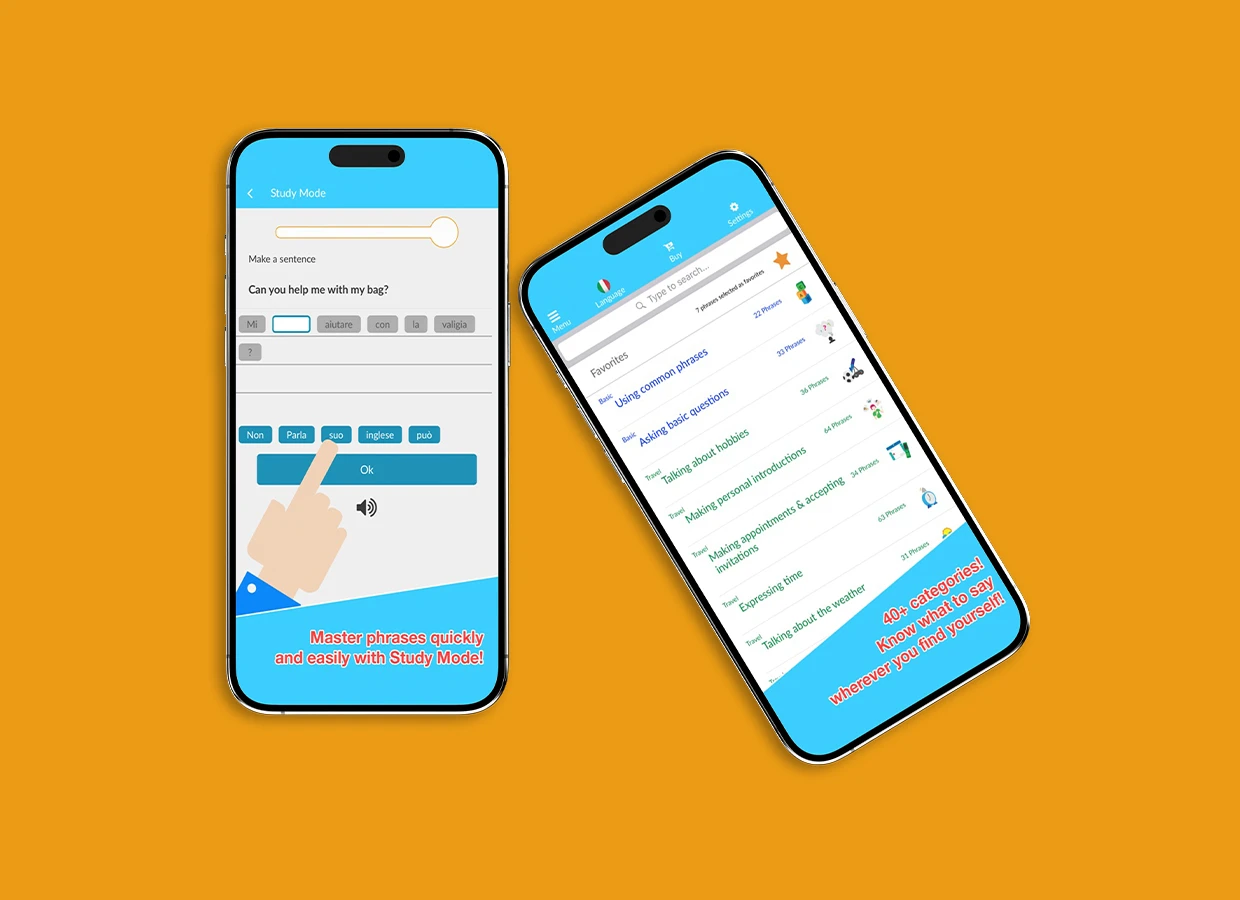
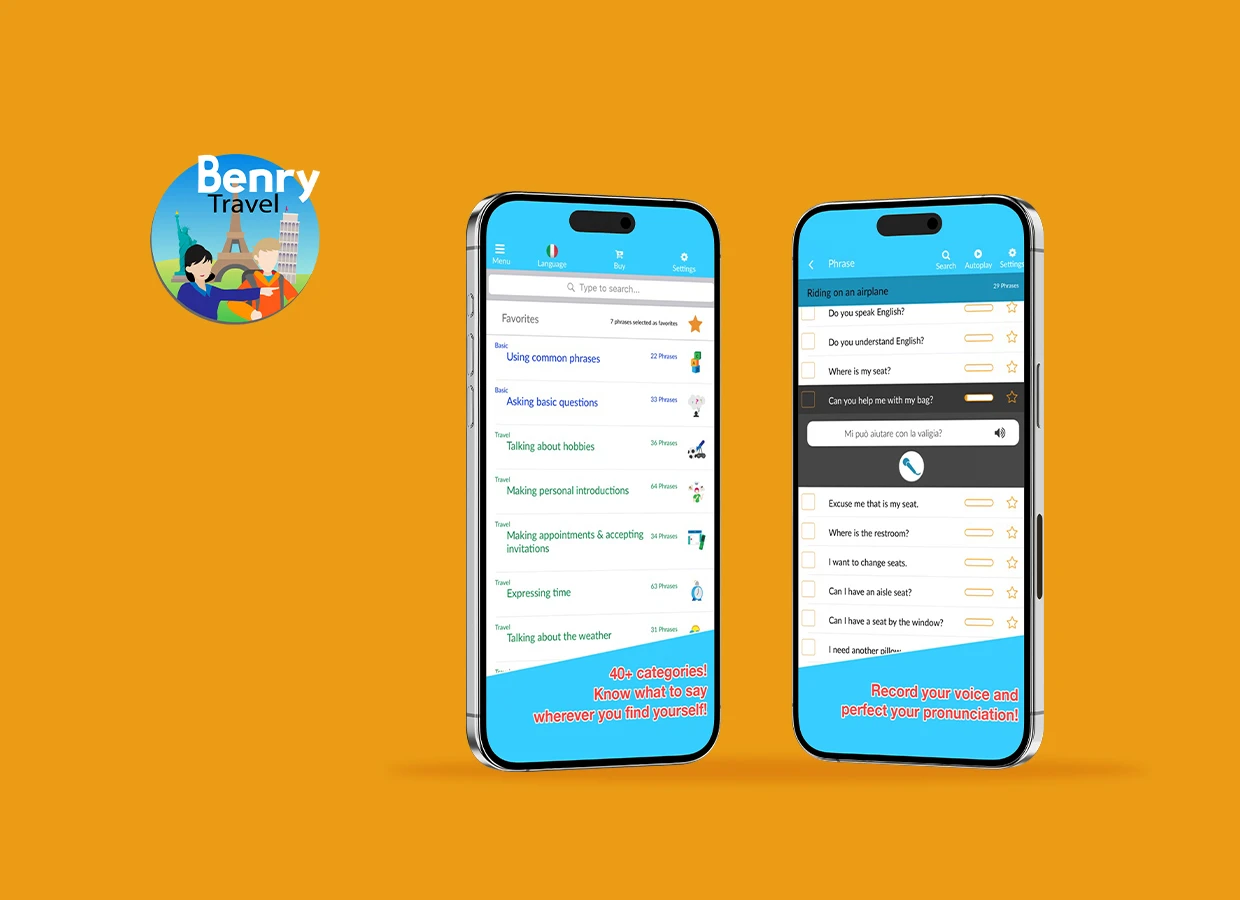
Discover how Benry Travel built a lightweight, scenario-based language learning app with offline access, ODR packs, and 1,000+ phrases for global travelers.
Tech Stack


Reema Health transformed home healthcare with a secure mobile app that streamlines communication, protects data, and simplifies patient management.
Tech Stack
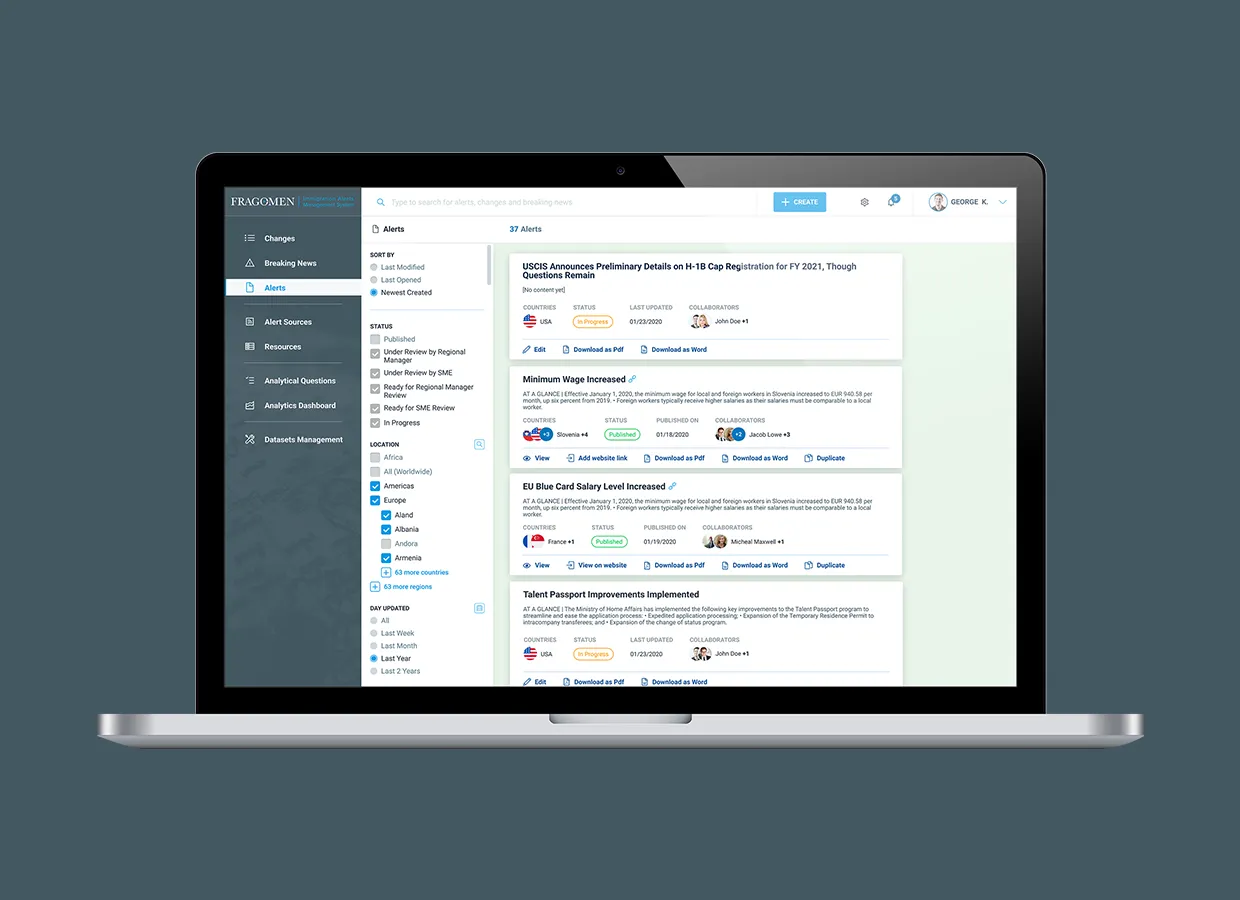
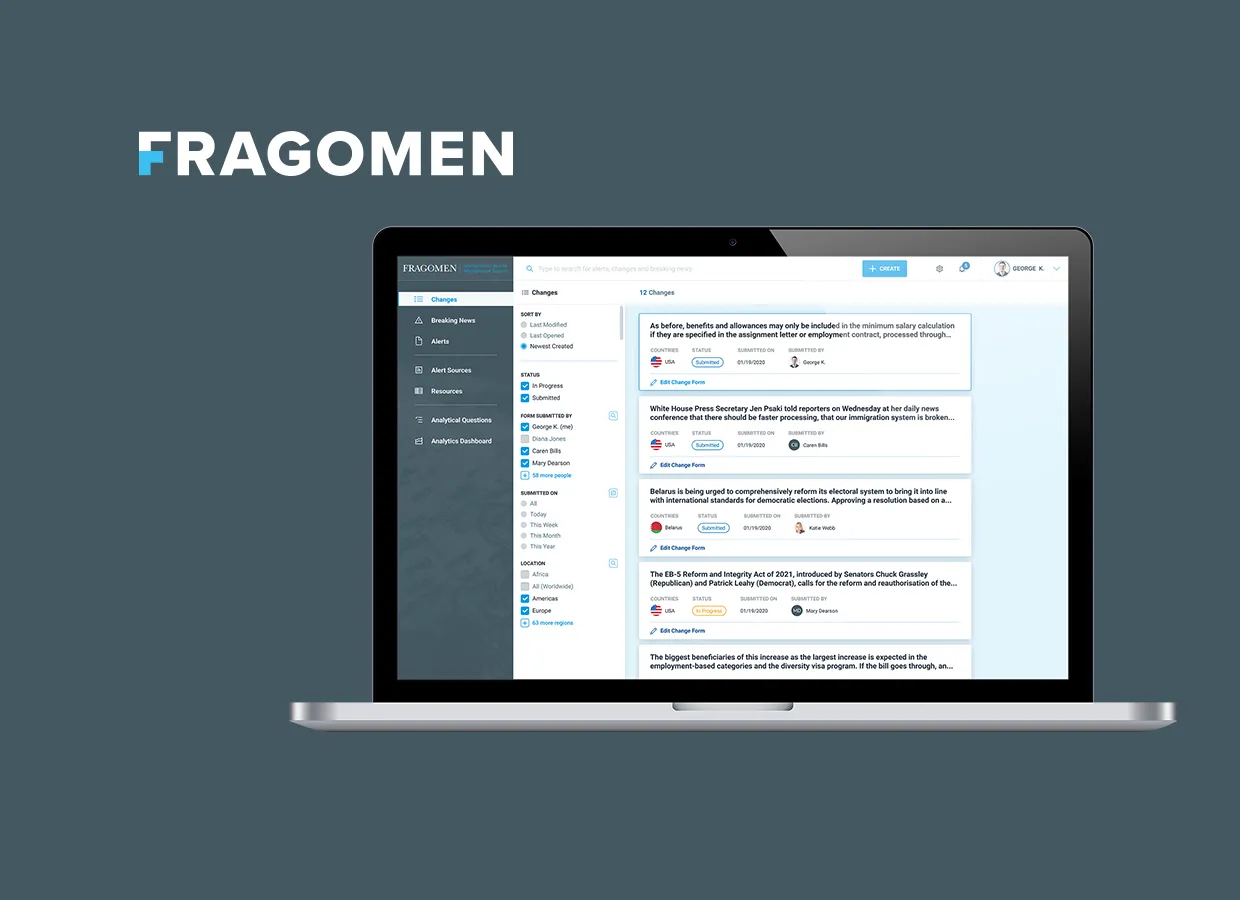
VT Netzwelt built a future-ready Immigration Alert System for Fragomen, enhancing workflows, compliance, collaboration, and data-driven decision-making.
Tech Stack
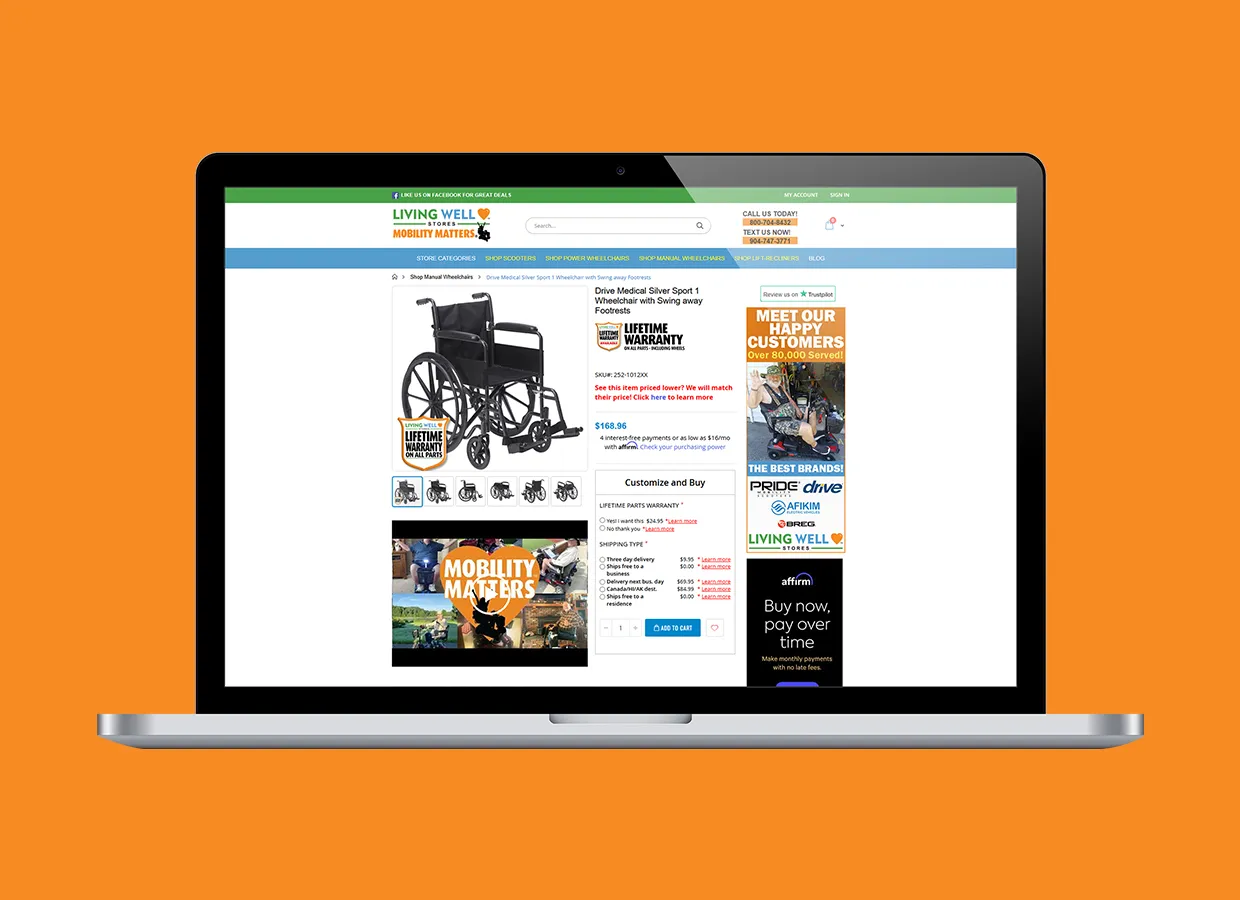

Transforming User Experience and Sales with Living Well Stores’ E-Commerce Enhancements
Tech Stack
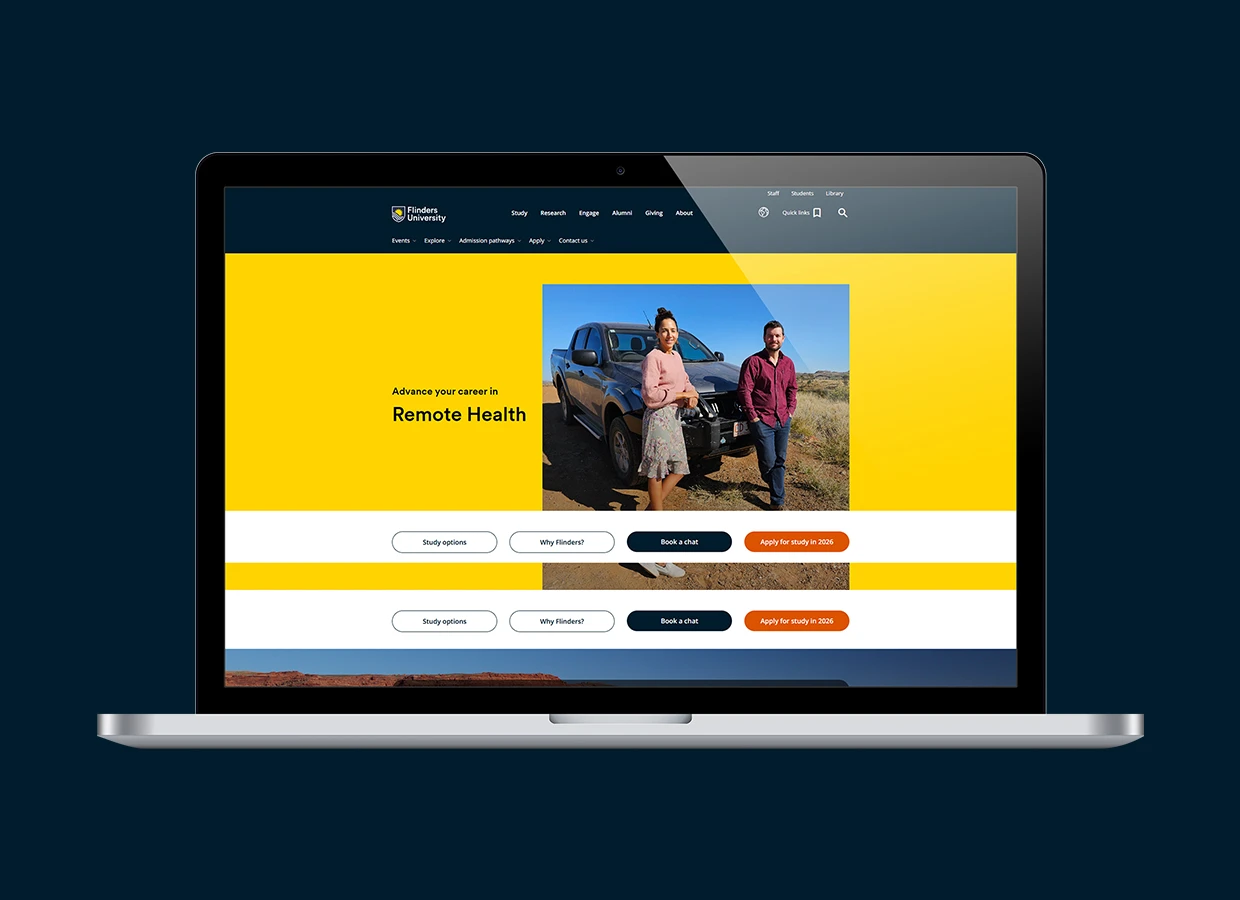
Redefining Healthcare Learning for Remote Australia with a Flexible, Low-Bandwidth LMS
Tech Stack
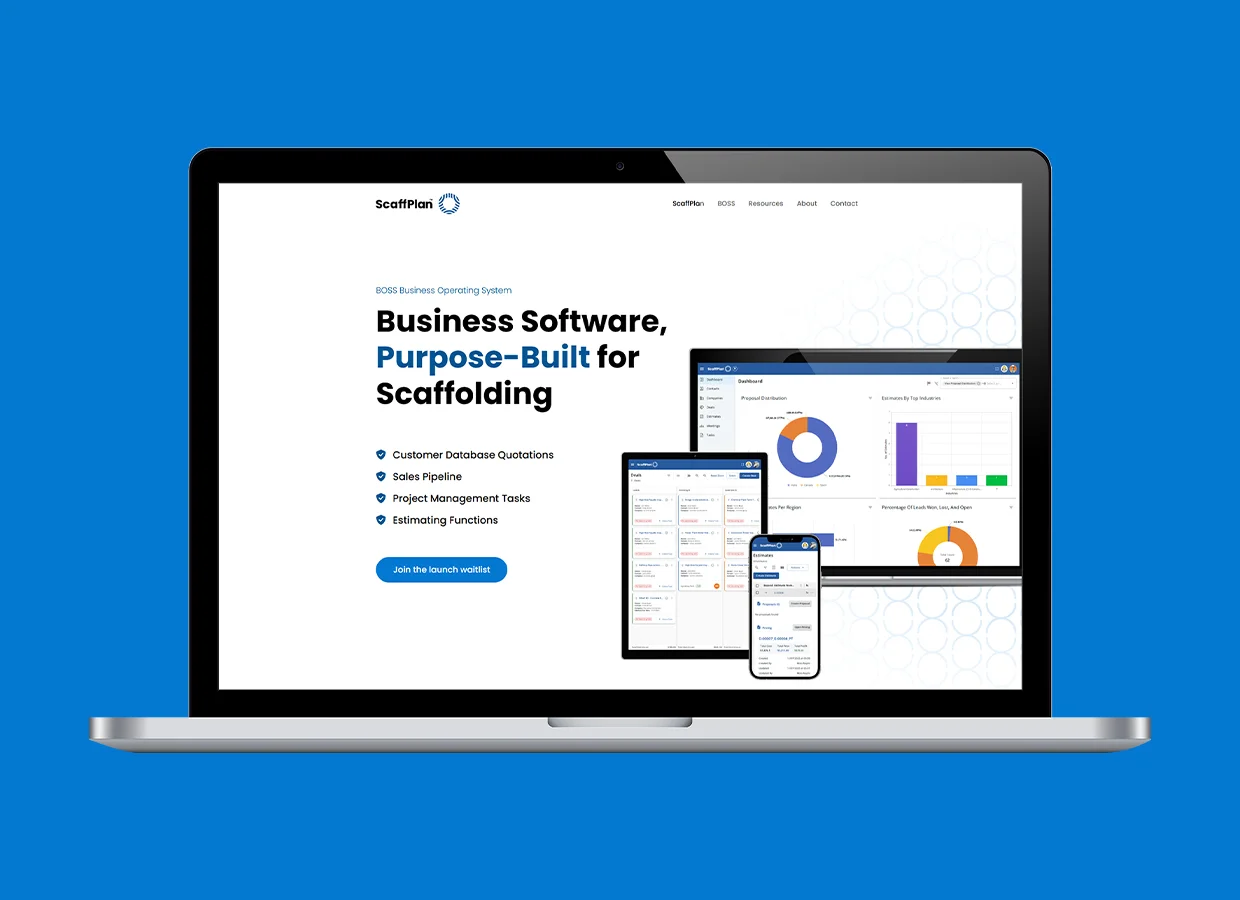
Digitizing ScaffPlan’s Sales Operations with Customized CRM Solution
Tech Stack


euGlide Platform: Addressing Diabetes Control with Innovation and Advanced Insulin Algorithms
Tech Stack

Maximizing Therapy Clinic Operations with A Powerful Unified Platform - S Cubed
Tech Stack